
More Compute, Please.
Even the most optimistic estimates underplayed the compute we need.

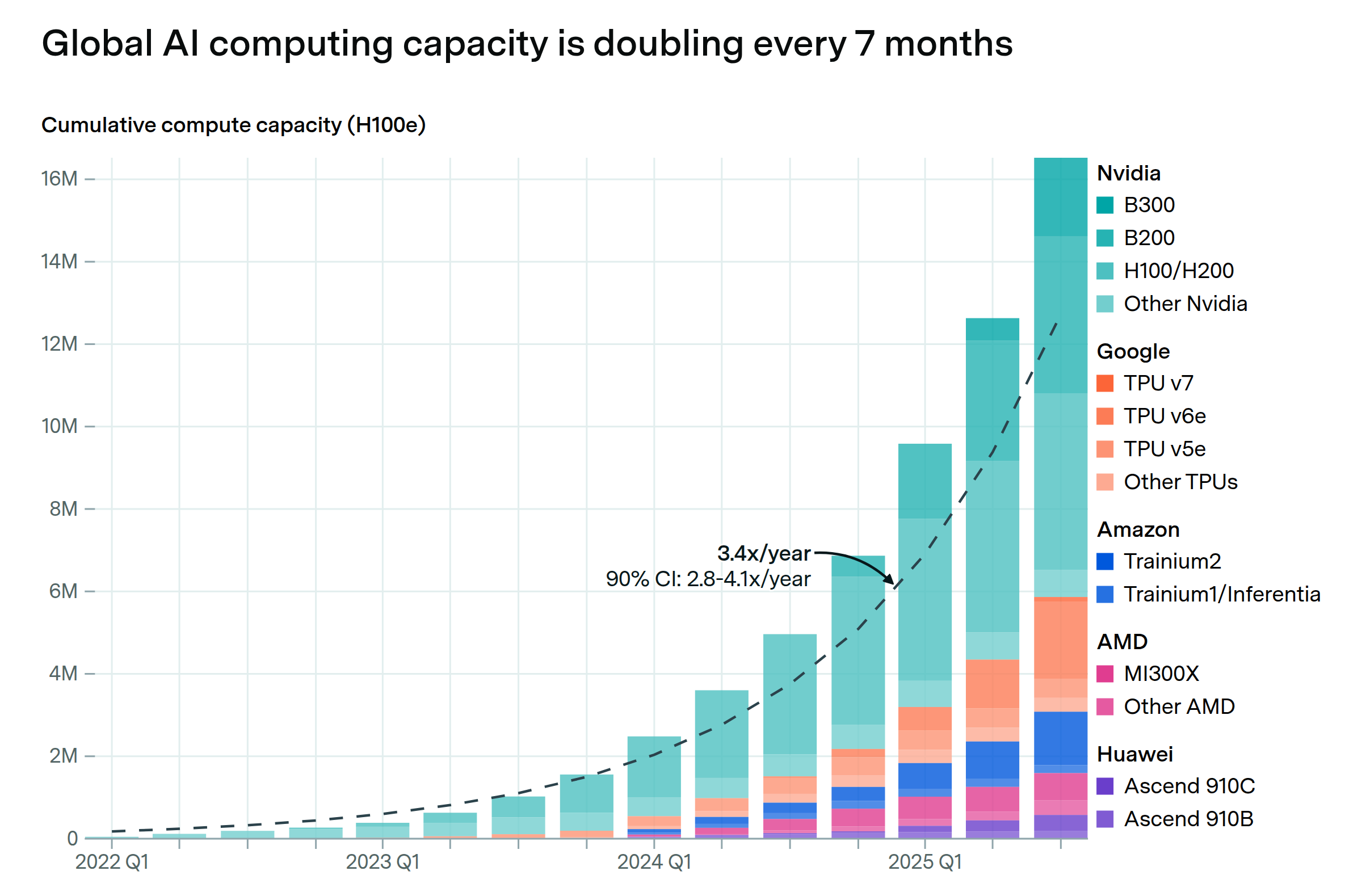
“As fast as we put the capacity in, it's being consumed.” — Andy Jassy, Amazon CEO, said this in Amazon’s Q1 earnings call last year.
Almost a year later, after he said the words above, we read in his annual letter earlier this week that:
Tarinium 2 capacity was sold out.
Trainium 3 is almost fully subscribed.
A part of Trainium 4 is already reserved.
Not ju…